CNATDA 第六章学习笔记
Introduction to the Link Layer¶
link layer 的主要任务是将 datagram 从当前 node 传输到另一个 node,还可以提供以下服务:
- framing:将 network layer 的 datagram encapsulate 成 link layer 的 frame 然后进行传输。
- link access:使用 medium access control(MAC)协议来决定传输哪一个 frame。对于 point-to-point 的传输是很简单的,但是对于 multiple access problem 来说,则需要 MAC protocol 来进行协调。
- reliable delivery:使用 acknowledgments 和 retransmission ,与 transport layer 的可靠传输服务类似。reliable delivery 在出错率较高的 links(如 wireless link)中采用较广,但是在出错率较低的 links 中则会造成不必要的 overhead,采用较少。
- error detection and correction:通过在 transmitting node 的 frame 中加入 error-detection bits 和在 receiving node 中进行 error check 来实现。link layer 的 error detection 主要在硬件层面上实现。
在 host 中,link layer 使用名为 network adapter(network interface controller,NIC) 的 chip 实现,属于硬件层面的实现。另外,还会有一部分由 CPU 上的软件实现。
Error-Detection and -Correction Techniques¶
error-detection and -correction 允许接收端偶尔的差错检测,但是不是永远都会进行,也就是说会存在未检测到的 error bits。
Parity Checks¶
实现 bit 层面上的 error detection 最简单的方法就是添加一个 parity bit 来记录原来值为 1 的 bits 的数目。这在只有一个 bit 会出错的情况下是 work 的,但是事实上 error 总是 clustered together in “bursts”,从而单个的 parity bit 行不通。
考虑采用 two-diminutional parity ,将要传输的 bits 分成一个二维矩阵,每一横、每一列都设置一个 parity bit,这样以来,不仅可以确定 error bit 的位置,还能进行 correction。
这种既能 detect 也能 correct 的能力叫做 forward error correction(FEC)。
Checksumming Methods¶
在 checksumming methods 中,d bits 的 data 会被分成 k bit 大小的整数序列,然后将这些整数的和作为 error-detection bits。 Internet checksum 就是这样的一种方法。在 TCP 和 UDP 中,所有 fields 包括 header 和 data 都会进行 Internet checksum ,而 IP protocol 中只有 header 会进行。
checksumming methods 需要相对少的 packet overhead,但是对 errors 的保护能力相对 link layer 采用 cyclic redundancy check 较弱。由于 transport layer 主要在软件上实现,需要的是 simple and fast 的差错检测能力,而 link layer 在硬件层面上实现使得能进行更复杂的 CRC 运算,所以 transport layer 采用的是 Internet checksumming 而 link layer 采用的是 CRC。
Cyclic Redundancy Check (CRC)¶
生成一个多项式来实现,详细的可以看 UCB CS70 Error Correcting Codes 或者看书,其实就是 CS 70 这个的 bit 版本。
Multiple Access Links and Protocols¶
network links 分为两种:point-to-point 和 braodcast。在 broadcast link 中,如果有多个 nodes 同时发送信息,则会产生 collision 。
为了解决 multiple access problem,需要一个 multiple access protocol ,主要有三类 multiple access protocols:channel partitioning protocols,random access protocols 和 taking-turs protocols。
一个合理的 multiple access protocol 需要满足以下条件:
- 只有一个结点发送消息则完全使用带宽
- 多个结点发送则平分带宽
- decentralized
- simple,inexpensive to implement
Channel Partitioning Protocols¶
TDM 将 time 分成 frames 然后每个 frame 又分成 slots,每一个 time slot 分配给一个 node。
FDM 则将频率分为 frames 再细分为 slots 。
FDM 和 TDM 都能保证每个 node 都能得到均分的传输速率,并且完全避免了 collision,但是也会导致只有一个 sender 时不能使用分配给其他 nodes 的 slots。
code division multiple access(CDMA)给每个 node 分配一个不同的 code,node 将 data 通过分配的 code 进行 encode 之后再发送。CDMA 在 wireless channel 中较常用。
Random Access Protocols¶
每个遭遇 collision 的结点都独立选取一个 random delay,在 delay 之后进行 retransmission。
ALOHA¶
假设每个 frame 大小相同,将 slot 的大小等于传输一个 frame 的时间,每个结点只会在 slot 的开始传输,并且所有结点是同步的,结点会在 slot 结束之前检测到 collision。
在 slotted ALOHA 中,结点在检测到 collision 之后立即停止传输,并且在之后的 slots 的开头以概率 \(p\) 进行传输直到成功,是 decentralized 。
恰好一个结点进行传输的 slot 被称为 successful slot,slotted multiple access protocol 的 efficiency 被定义为 successful slot 的占比。显然,有 \(n\) 个 active nodes 的时候,efficiency 为 \(np(1-p)^{n-1}\) ,当 \(n\) 很大时,它的最大值为 \(1/e\approx 0.37\)。
在 pure ALOHA 中,不进行 slot 的划分,是 fully decentralized 的,并且每个结点遭遇 collision 之后会以概率 \(p\) 立即重传,尽管更加去中心化,但是它的 efficiency 也只有 slotted ALOHA 的一半了。
Carrier Sense Multiple Access with Collision Detection (CSMA/CD)¶
CSMA 基于 “Listen before speaking” 的原则进行 carrier sensing,而 CSMA/CD 则是 CSMA 加上 “If someone else begins talking at the same time, stop talking” 的原则进行 collision detection。
由于 channel propagation delay 的存在,一个结点在检测到另一个结点发送过消息前可能已经发送过一段消息了。
在 CSMA/CD 中,结点遇到 collision 会随机等到一段时间再进行重传,这个等待时间由 binary exponential backoff 算法进行计算:当前如果累计检测到了 \(n\) 次 collision,则在 \(\{0,1,2,\dots,2^n-1\}\) 中随机取一个数作为 \(K\) ,然后等待传输 \(K\cdot 512\) bit 的用时,当 \(n\) 超过 10 的时候则取 10。如果等待之后传输成功,则 \(n\) 重新变为 0。
CSMA/CD 的 efficiency 约为 \(\dfrac{1}{1+5d_{\mathrm{prop}}/d_{\mathrm{trans}}}\) ,其中 \(d_{\mathrm{prop}}\) 表示 propogation delay,\(d_{\mathrm{trans}}\) 表示一个 maximum-size frame 的传输用时。
Taking-Turns Protocols¶
taking-turns protocol 的主要思想是让结点轮流发送消息。
polling protocol 中存在一个 master node,它轮流 poll 每个结点让其发送不超过 maximum number 个 frame,发送完再继续 poll 下一个结点。polling protocol 是 centralized 的,master node 倒下了整个系统就会崩溃,同时也引入了 polling delay:对 inactive nodes 进行 poll 会浪费时间。
token-passing protocol 中每个结点以固定顺序向下一个结点发送 token,当结点需要传输时则会先传输不超过 maximum number 个 frame 再传递 token。token-passing protocol 是 decentralized 并且高效的,但是当一个结点崩溃了同样会使得整个 channel 崩溃,需要采取 recovery procedure。
### DOCSIS: The Link-Layer Protocol for Cable Internet Access
DOCSIS 用于 cable access network,将一个 residential cable modems 连接到 cable modem termination system(CMTS),同时用到了多种 multiple access protocol。
DOCSIS 使用 FDM 分为 downstream 和 upstream 两个 channel,downstream channel 的内容由 CTMS 向 cable modem 发送,不存在 multiple access problem。upstream channel 则被分为了多个 mini-slots,这些 slots 由 CMTS 通过 downstream 动态分配,需要由 cable modem 发送 mini-slot-request-frame,这些 requests 通过一些特殊的 mini-slots 以 random access 的方式发送,通过是否收到 CMTS 回复的 mini-slots 来判定 collision 的存在,使用 binary exponential backoff。
## Switched Local Area Networks
### Link-Layer Addressing and ARP
host 和 router 的每个 adapter 都有一个 LAN address (physical address/MAC address) ,对于有多个 interface 的 router 来说,每个 interface 都会有一个 MAC address。
MAC address 的长度为 6 bytes,由 IEEE 进行分配,每个 adapter 的 MAC address 都是固定不变的。
当 adapter 需要发送 frame 给目的 adapter 时会将目的 MAC address 插入 frame 然后送往 LAN,由 switch 将其向所有的 interfaces 进行 broadcast,与目的 MAC address 匹配的就会接收,否则丢弃。
MAC broadcast address 为 ff:ff:ff:ff:ff:ff。
### Address Resolution Protocol
ARP 是用来将 subnet 内部的 IP address 转换成 MAC address 的。
每个 host/router 内部维护一个 ARP table,存储 IP 到 MAC 地址的映射,同时会有一个 TTL,到期则会丢弃这条记录。
当 ARP table 中没有对应的 MAC 地址时,sender 会发送一个 ARP request,其中目的 MAC 地址为 MAC broadcast address,对应的 receiver 收到后会发送 ARP response,一般不是 broadcast。sender 收到 response 后更新 ARP table。通过这种机制,ARP table 可以自动构建,不需要手动配置。
如果需要向 subnet 外发送信息,则是需要发送给 gateway(first-hop router),需要查询的也是 gateway 的 MAC 地址,gateway 收到 frame 后会传递给它的 network layer 将 source IP address 修改为它的 IP address。
ARP 是一个位于 network layer 和 link layer 之间的 protocol。
### Ethernet
Ethernet 通常使用 hub 或 switch 来连接各个 interface。hub 会将收到的每个 bit 转发给所有 interfaces,容易造成 collision。switch 根据 MAC protocol 进行转发,避免了 collision。
Ethernet 的 frame 通常由以下部分组成:
- data field(46 to 1500 bytes):IP datagram。如果 IP datagram 的长度小于 46 bytes,则会填充至 46 bytes,network layer 通过 IP datagram 的 length field 来去除填充。
- destination field(6 bytes)
- source field(6 bytes)
- type field(2 bytes):标识 upper layer protocol。
- CRC checksum(4 bytes)
- preamble(8 bytes):标识 frame 的开头并同步时钟。
Ethernet technologies 提供的是 connectionless、unreliable 的服务。
Link-Layer Switches¶
switch 的主要任务是将 incoming frames forward 到 outgoing links。switch 是 transparent 的,也就是说,host 和 router 并不知道它的存在,它也不需要手动配置,是 plug-and-play 的。
switch 的每个 interface 都有一个 output buffer,与 router 类似。
switch 主要有两个功能:filtering 和 forwarding。它们通过维护一个 switch table 来实现:存储 MAC 地址和对应的地址,另外还有过期时间。
当从 interface \(x\) 中收到 destination MAC address 为 \(\alpha\) 的 frame 时:
- 若 \(\alpha\) 不在 switch table 中,则 broadcast。
- 若 \(\alpha\) 对应的 interface 为 \(x\) 时,则 discard。
- 若 \(\alpha\) 对应的 interface 不等于 \(x\) 时,则 forward。
switch 是 self-learning 的:如果在 intreface \(x\) 中收到了 source MAC address 为 \(x\) 的 frame 会在 table 中添加相应的记录。
相比 hub,switch 具有以下优势:
- 消除了 collision。
- 可以将不同 technology 的 links 连接在一起。
- 提供 network management 服务,如 enhanced security 等。
switch 和 router 各自具有 pros 和 cons:
- switch 即插即用,无需手动配置;只有 2 layers,性能更好;只能练成 spanning tree,不能形成环;如果 subnet 内 host 太多会影响性能;可能遭受 broadcast storm。
- router 需要手动配置;有 3 layers,性能略差;可以随便连,从而提供多个 route 供 routing protocol 使用,实现 best path;提供 firewall 防止 broadcast storm。
一般来说,几十上百个 host 使用 switch 即可,更多的需要 router 进行中转。
Virtual Local Area Networks (VLANs)¶
LANs 存在以下一些限制:
- 缺少对 traffic 的限制,例如未被学习到的 MAC 地址发送的 ARP 仍需 traverse 整个 subnet,降低了性能。
- switch 的 ports 数量不足以匹配 subnet 内 host 的数量。
- 要在不同的 subnet 之间移动 host 需要更改物理接线。
VLAN 可以解决这些问题。它通过软件对 switch 的 ports 进行配置,将 ports 划分为不同的 group,每个 group 都属于一个 subnet。为了将不同 subnet 相连,可以使用一个 router 将这两个 switch 连接起来,为了方便,很多 switch 都自带一个 router。
可以使用 VLAN trunking 将分属于不同 switch 上的 port 连接起来作为一个 VLAN:每一个 switch 上有一个 trunk port,将需要 trunking 的 switch 通过 trunk port 相连,发送到对面 switch 的 VLAN 的 frame 会被 forward 到 trunk port。 trunking 时使用的是 extended Ethernet frame format 802.1Q,由发送端的 switch 将对应的 VLAN tag 加入 header 来对 VLAN 进行标识。
除了基于 switch port 的 VLAN,还有基于 MAC address 和 network protocol 的 VLAN。
Multiprotocol Label Switching (MPLS)¶
MPLS 采取了一个重要的概念:定长的 label 来优化 IP router 进行 forward 的速度。它仍然使用的是 IP addressing 和 routing,但是在 link layer header 和 network layer header 之间加入了一个 MPLS header,它由 label、exp、s、TTL 组成。
MPLS frame 仅仅能在支持 MPLS 的 router 之间进行传输,在处理 MPLS datagram 时,router 不需要将 destination IP 展开并在 forwarding table 中 look up 来进行 longest prefix match。
MPLS 可以潜在提升 switching speed,也带来了新的 traffic management 的能力,如 VPNs。
Data Center Networking¶
大型互联网公司建造了许多 data centers,它们对外接入 Internet,对内存在一套 data center networks。
data center 主要提供 3 种服务:provide content、distributed computing、cloud computing。
data center 内的 hosts 称为 blades,几十个 blades 组成一个 rack,每个 rack 有一个 switch,被称为 Top of Rack (ToR) switch。
data center network 支持两种 traffic:外部的 clients 与内部的 hosts 之间的 traffic、内部的 hosts 之间的 traffic,为了支持第一种 traffic,设有 border routers 来连接 Internet。
另外,为了分配外界大量的 requests,data center network 中设有 load balancer 来分配这些 requests 给不同的但是提供相同内容的 hosts 从而平衡 load,同时 load balancer 还起到了一个 NAT-like 的功能。
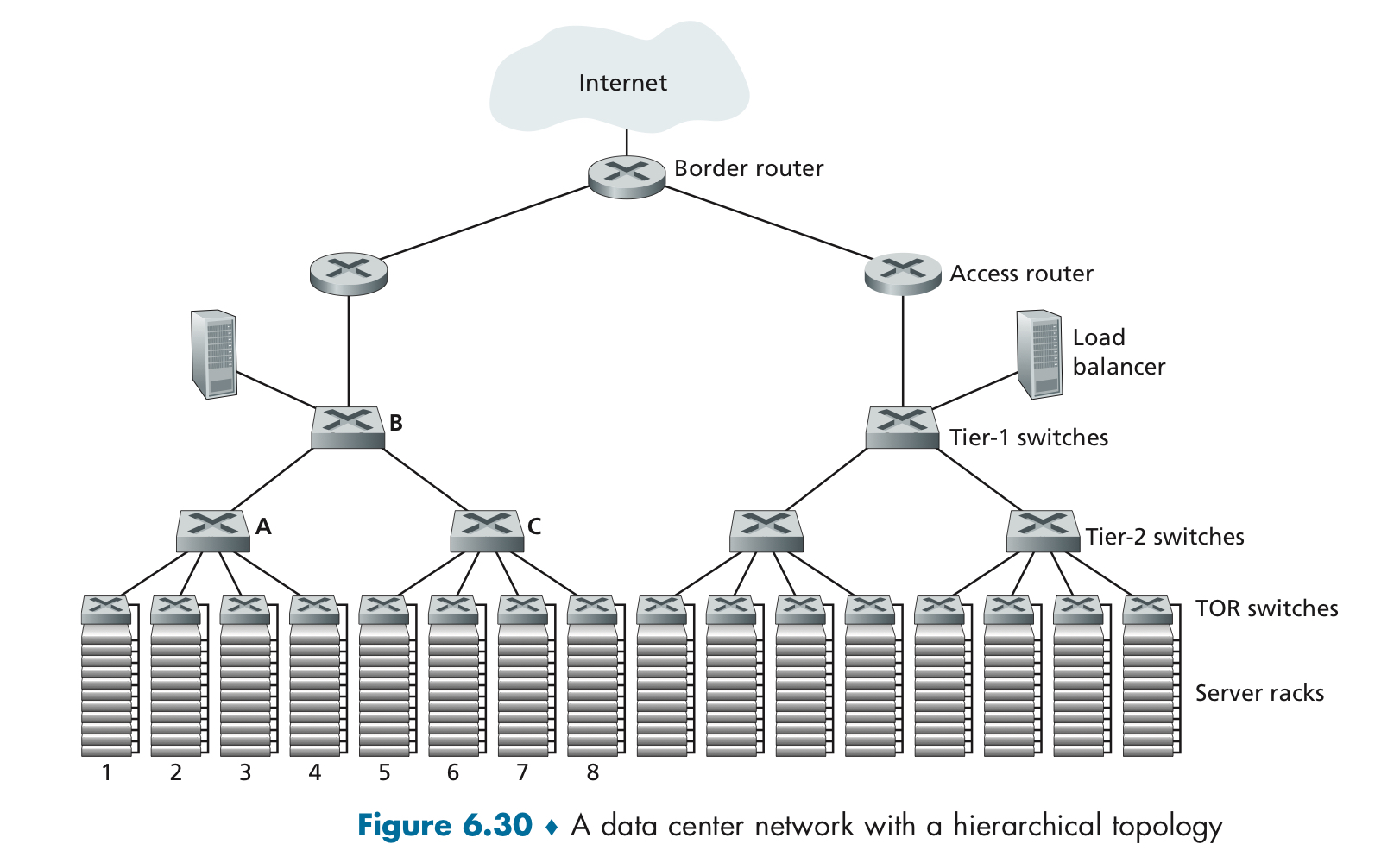
树状的网络结构使得 data center 可以拥有上万个 servers,但是也存在着 limited host-to-host capacity 的问题。解决这个问题有 3 种方法:
- 部署更高速率的 switch 和 router,这样开销会很大。
- 将需要互相通信的 host 尽量放在一个子树下,这样不容易做到且灵活性较低。
- 将相邻两层级的 switch 之间互相连通,增加 interconnection 的数量,这样在优化性能的同时也增加了系统的稳定性。
data center 通常使用 SDN 来对网络进行集中式管理。
为了方便 cloud computing 和网络管理,data center 使用 virtual machine 来将软件与硬件进行 decouple。为了方便 VM 在不同 host 之间移动,可以将整个 data center network 看成是一个 single、flat、layer-2 network。要使所有的 hosts 看上去是与单个的 switch 相连,可以将 ARP 的机制改成一个类似 DNS query 的机制,并且维护一张分配给 VM 的 IP 地址到 VM 对应的 ToR switch 的映射表。
data center 内部的 hosts 有限,因此内部 network 的 buffer size 和 delay 也很小,并且 congestion control 会降低性能,因此一般使用针对 data center 的 TCP protocols。
modular data center (MDC) 是一个由至多数千个 hosts 组成的 container,当 MDC 内部的某个 component 坏掉时,MDC 可以以 degraded performance 继续工作,当很多 components 都坏掉的时候,整个 MDC 就会被丢弃。
很多公司会定制他们的 data center 内的几乎一切内容。
Amazon 使用 “available zones” 将 data center 在邻近但是位置不同的地方进行复制,从而提供 fault tolerance,也保证了 low latency,提高了服务的可靠性。